
Golang 大杀器性能剖析 PProf
原因:组内大部分同学接触Go时间不长,对Go的一些生态工具不是特别了解,比如PProf,通过技术分享共同学习
目标:对PProf的原理和使用有基本了解,提供一种分析线上问题的新思路,在以后的工作中能够已备不时之需
PProf简介
PProf 是用于可视化和分析性能分析数据的工具,PProf 以 profile.proto 读取分析样本的集合,并生成报告以可视化并帮助分析数据。
PProf的实现位置:
- runtime/pprof:采集器,负责采集应用程序的运行数据供给 pprof 可视化工具
- net/http/pprof:通过一个 HTTP Server 将 prof 数据进行可视化分析,实际上其底层也是调用的 runtime/pprof 提供的函数,封装成接口对外提供网络访问。
PProf提供的类型:
- CPU profiling(CPU 性能分析):这是最常使用的一种类型。用于分析函数或方法的执行耗时
- Heap profiling:这种类型也常使用。用于分析程序的内存占用情况
- Block profiling:这是 Go 独有的,用于记录 goroutine 在等待共享资源花费的时间
- Mutex profiling:与 Block profiling 类似,但是只记录因为锁竞争导致的等待或延迟
- 等
PProf的应用时机:
线上突发报警,接口超时,错误数增加,除了看日志、监控,就是用性能分析工具分析程序的性能,找到瓶颈。
当然,一般这种情形不会让你有机会去分析,降级、限流、回滚才是首先要做的,要先止损。回归正常之后,通过线上流量回放,或者压测等手段,制造性能问题,再通过工具来分析系统的瓶颈。
PProf原理
【CPU Profiling】
CPU Profiling 工具基本分两种思路:
- 插桩:具体实现方式就是在每个函数的开始和结束时计时,然后统计每个函数的执行时间。
注:插桩计时本身也会带来性能消耗,并且对于正在运行的程序没办法插桩。
- 采样:具体实现是注入正在运行的进程,高频地去探测函数调用栈。根据大数定律探测次数越多的函数运行时间越长。
CPU Profiling 原理图如下:
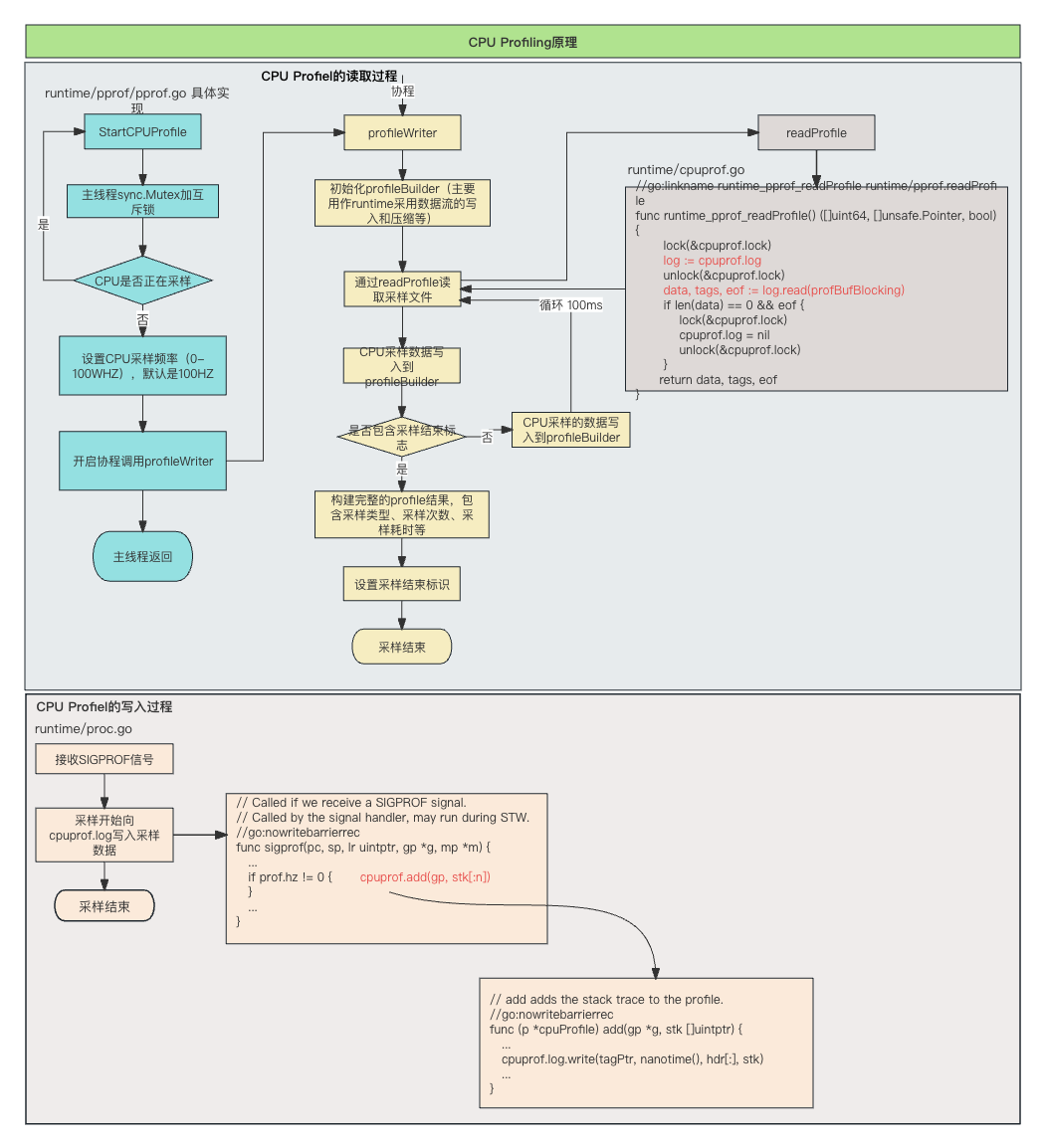
具体实现流程图如下:
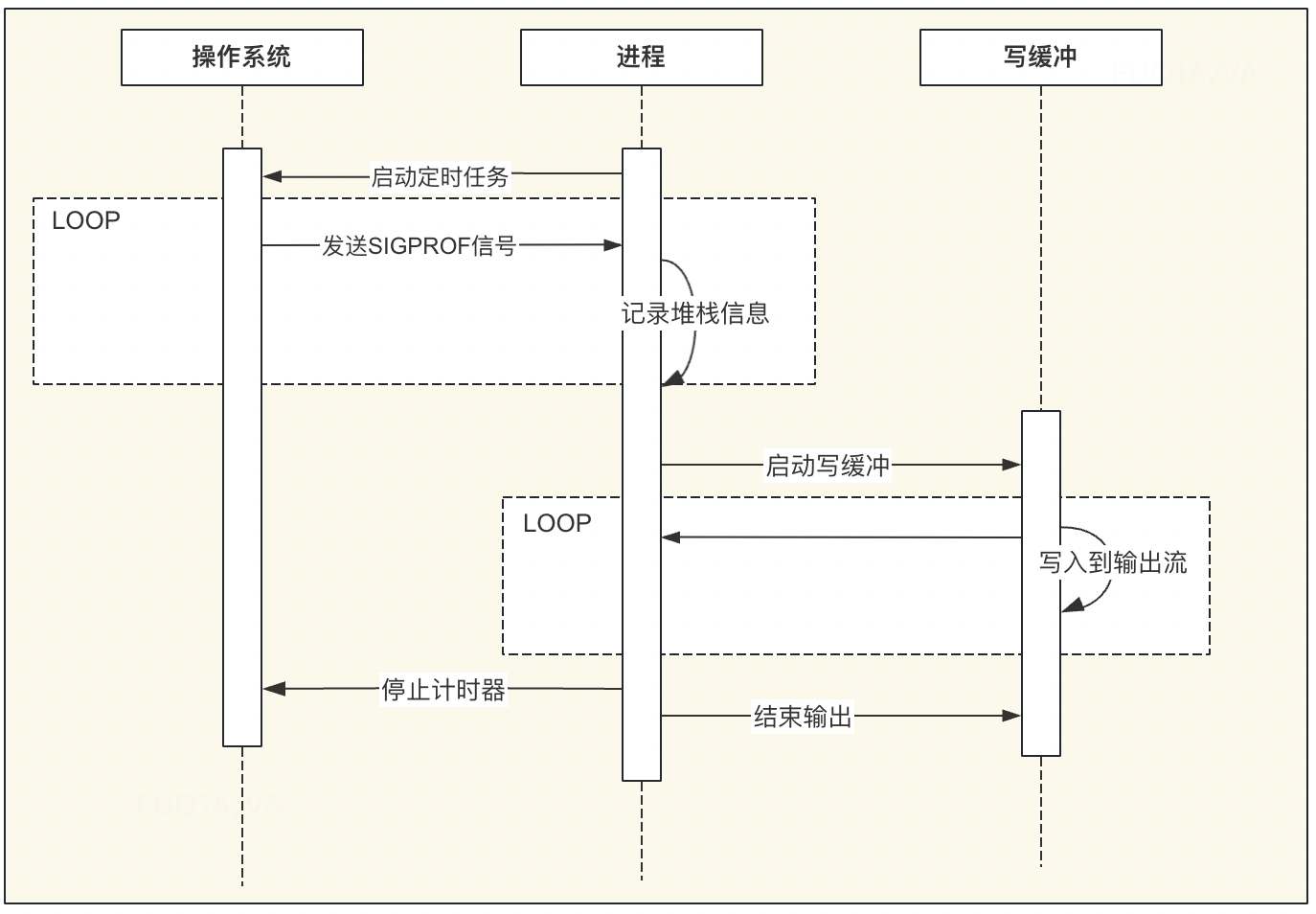
SIGPROF信号量:SIGPROF is sent when CPU time used by the process and by the system on behalf of the process elapses.
具体实现过简单就是一个简单的生产者和消费者模型
- CPU Profiler 会向目标程序注册一个定时执行的 hook(有多种手段,譬如 SIGPROF 信号),在这个 hook 内我们每次会获取应用程序此刻的 stack trace
- 程序收到 SIGPROF信号,将 CPU 采样数据写入到 cpuprof.log 的 buffer 缓存中
- 然后 profileWriter 中死循环调用 readProfle,读取采样数据,将数据写入到指定的 cpu.prof 文件中
- 将采集到的所有样本进行聚合,最终得到每个函数被采集到的次数,相较于总样本数也就得到了每个函数的相对占比
【Heap Profiling】
与 CPU Profiling 不同的是,Heap Profiling 的数据采集工作并非简单通过定时器开展,而是需要侵入到内存分配路径内,这样才能拿到内存分配的数量。所以 Heap Profiler 通常的做法是直接将自己集成在内存分配器内,当应用程序进行内存分配时拿到当前的 stack trace,最终将所有样本聚合在一起,这样我们便能知道每个函数直接或间接地内存分配数量了
Heap Profile 的 stack trace + statistics 数据模型与 CPU Proflie 是一致的
引入关键问题:
Q1: 堆分配操作的调用栈信息是在什么时候获取的?
A1: 调用栈信息是在goruntime分配内存时采样获取的
/runtime/malloc.go
1 | if rate := MemProfileRate; rate > 0 { |
- MemProfileRate<=0:不采样
- MemProfileRate=1:每次分配都记录
- MemProfileRate>1:每分配满若干字节采样一次。这里的若干字节不是一个严格固定的值,而是以MemProfileRate为均值的指数分布中随机取一个值。这是为了避免内存分配有固定的规律,如果严格按固定字节数采样,可能会每次都刚好采到特定类型的分配。
MemProfileRate的默认值为512*1024,即每分配512KB(近似),就采样一次。MemProfileRate的值可以通过GODEBUG=”memprofilerate=xxx”来修改。
Heap Profile是如何写入的?
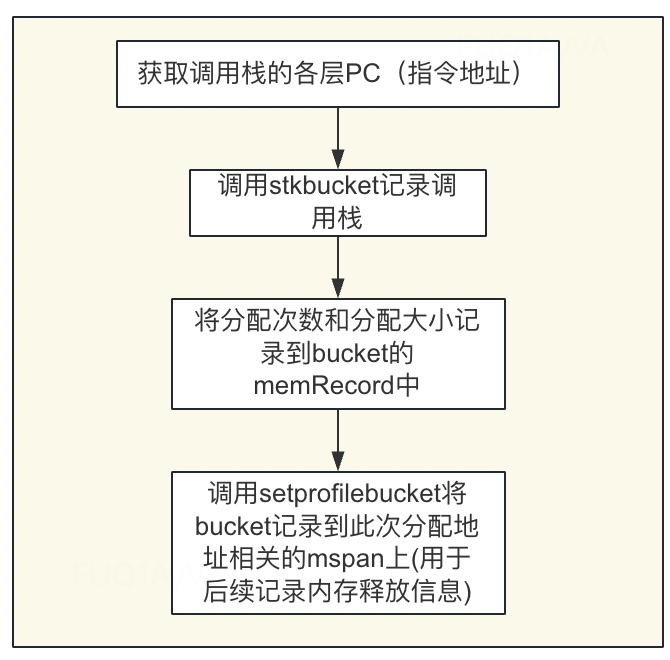
调用栈的信息主要通过/runtime/mprof.go的mProf_Malloc中实现
1 | // Called by malloc to record a profiled block. |
大致流程如下:
Heap Profile是如何输出的?
// WriteHeapProfile is shorthand for Lookup(“heap”).WriteTo(w, 0).
// It is preserved for backwards compatibility.
Interface 1:pprof.WriteHeapProfile
Interface 2: Lookup(“heap”).WriteTo(w, 0)
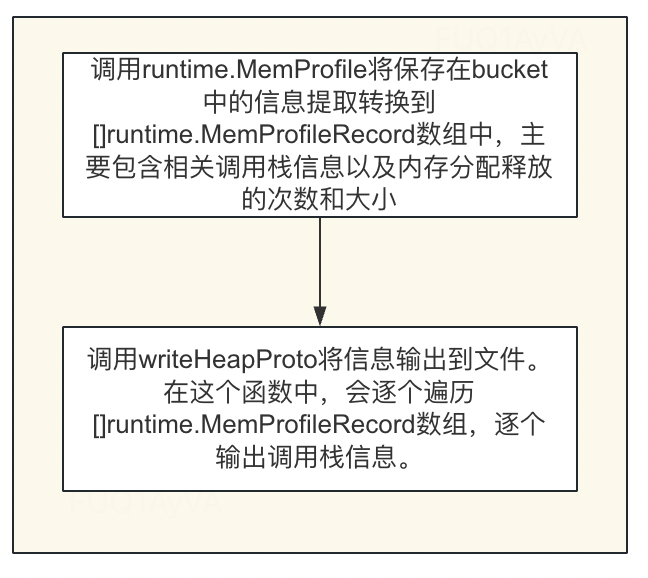
底层都是调用writeHeapInternal,主要针对该方法进行分析
1 | func writeHeapInternal(w io.Writer, debug int, defaultSampleType string) error { |
大致流程如下:
PProf实验
实验准备:
- 源代码
1 | go get -d github.com/wolfogre/go-pprof-practice |
- 工具
Graphviz 可视化工具(非必须,主要为了web可视化需要使用)
方法一:brew install graphviz
方法二:sudo port install graphviz(备选)
简要分析:
1 | package main |
启动服务:
1 | go build |
top命令查看CPU占用情况
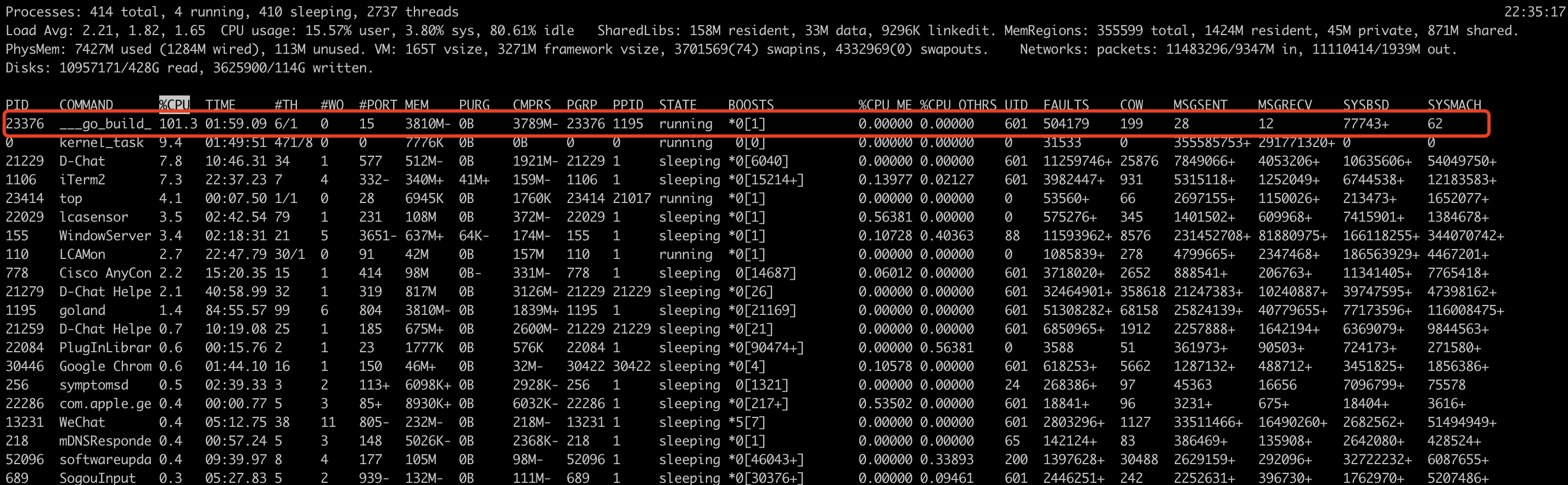
究竟是什么原因导致了CPU飙升呢?PProf出场了
可以通过 报告生成、Web 可视化界面、交互式终端 三种方式来使用 pprof。
- 报告生成
查看启动http接口,原始采样信息
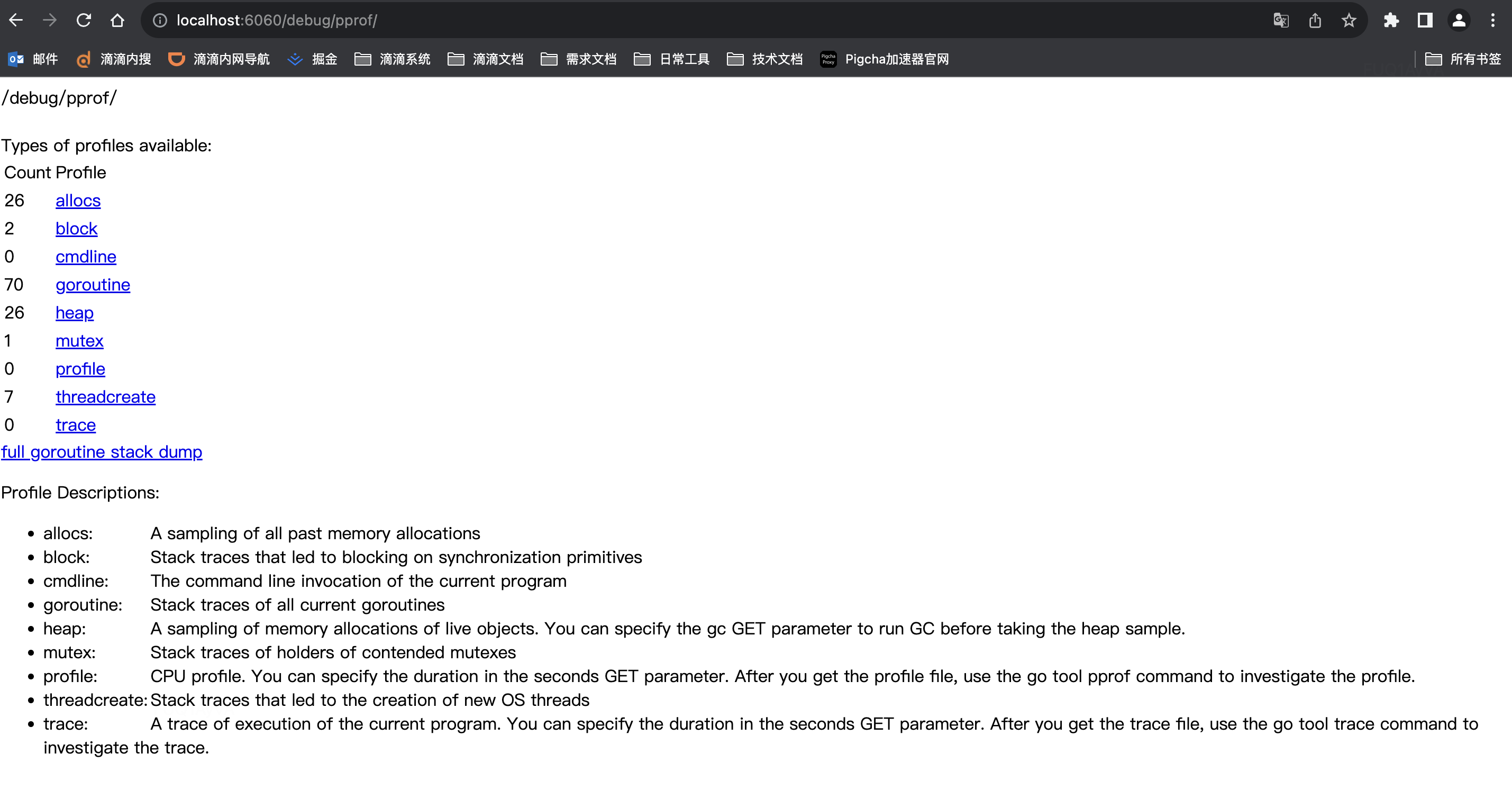
打开上面的文件都是原始采样信息,由于直接阅读采样信息缺乏直观性,我们需要借助 go tool pprof 命令来排查问题,这个命令是 go 原生自带的,所以不用额外安装。
- Web可视化操作页面
利用go tool pprof进行可视化分析:
基于HTTP接口分析
1 | go tool pprof -http=:8000 -seconds 20 http://127.0.0.1:{port}/debug/pprof/profile |
基于文件分析
1 | go tool pprof -http=:8000 {path} |
PProf问题排查
排查CPU占用过高
步骤一:从整体分析哪些方法引起的CPU增高?
方式一:通过top查看:
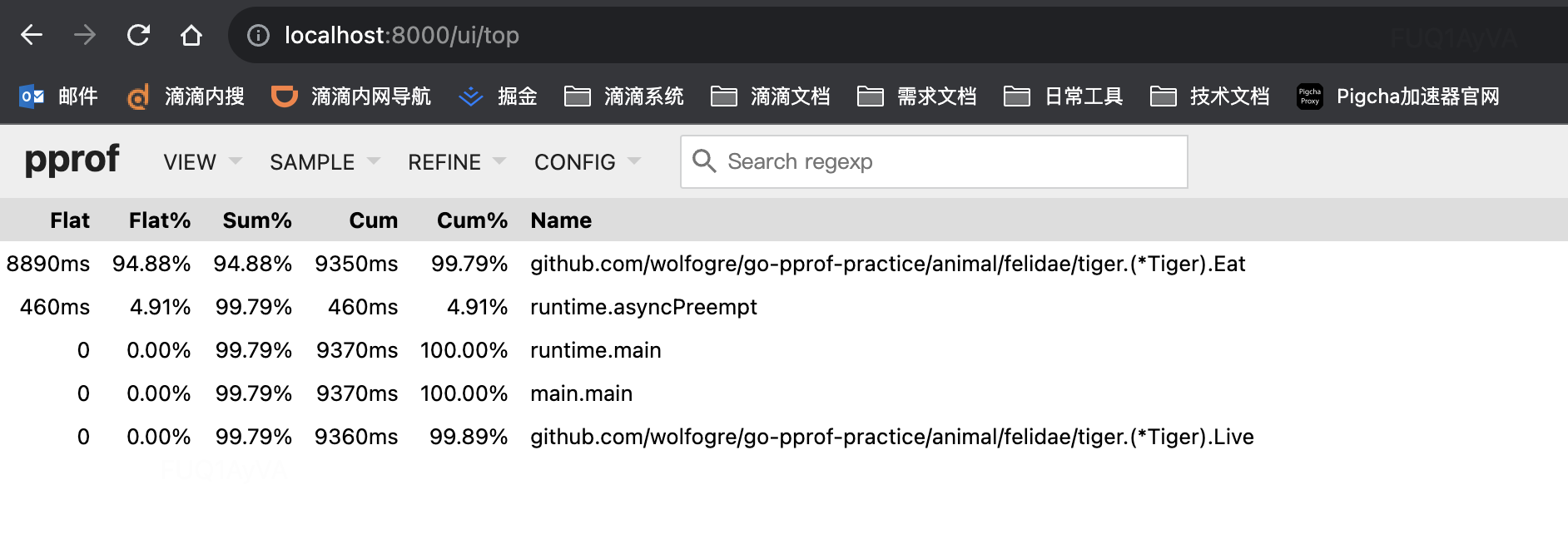
列名 含义 Flat 函数自身的运行耗时 (不包含这个方法中调用其他方法所占用的时间) Flat% 函数自身在 CPU 运行耗时总比例 Sum% 函数自身累积使用 CPU 总比例 Cum 函数自身及其调用函数的运行总耗时 Cum% 函数自身及其调用函数的运行耗时总比例 Name 函数名
通过top图初步定位CPU占高是 github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat 造成的
方式二:通过Graph连线图查看:
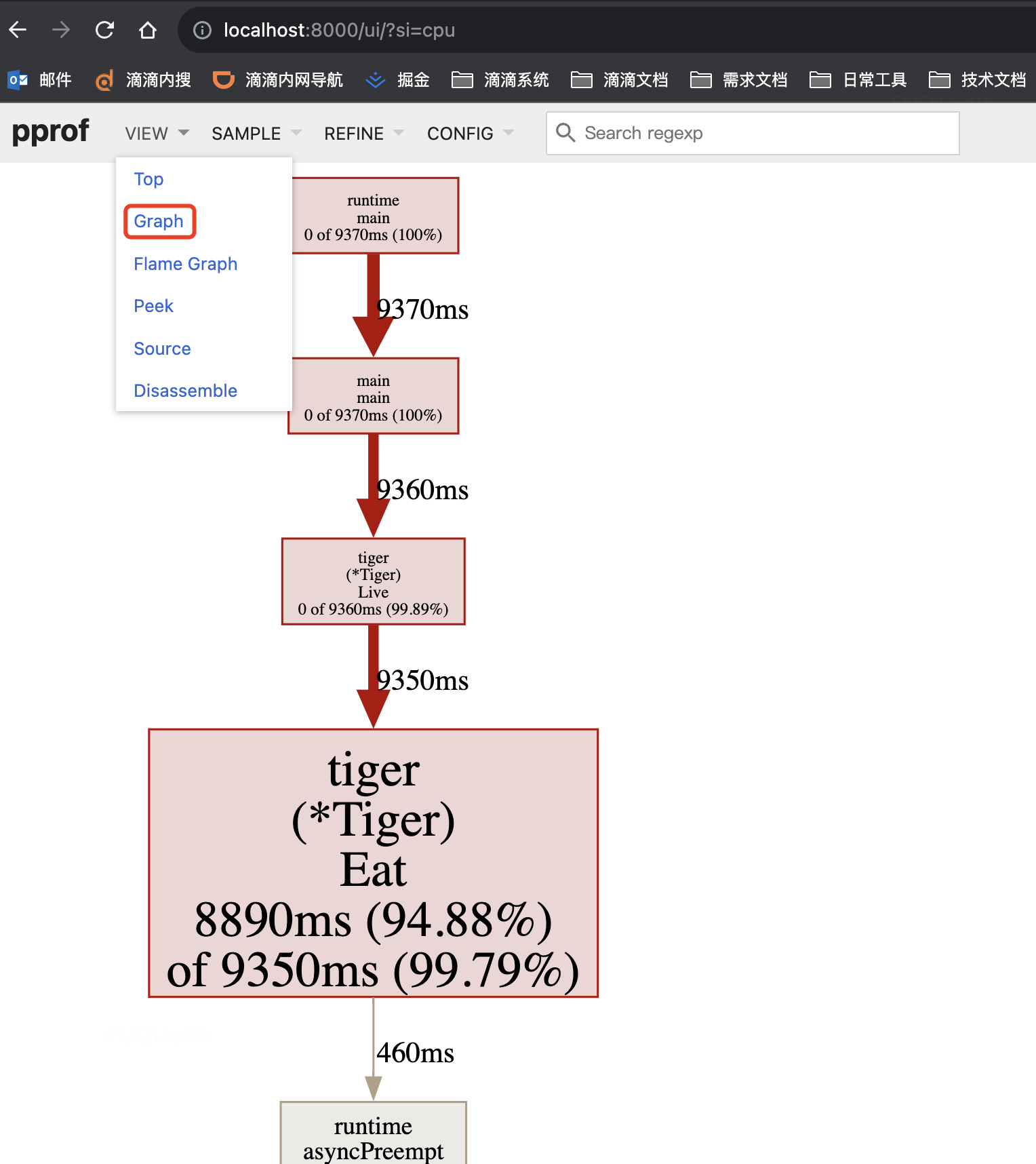
通过连线图初步定位CPU占高是 github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat 造成的
- 方式三:通过火焰图查看
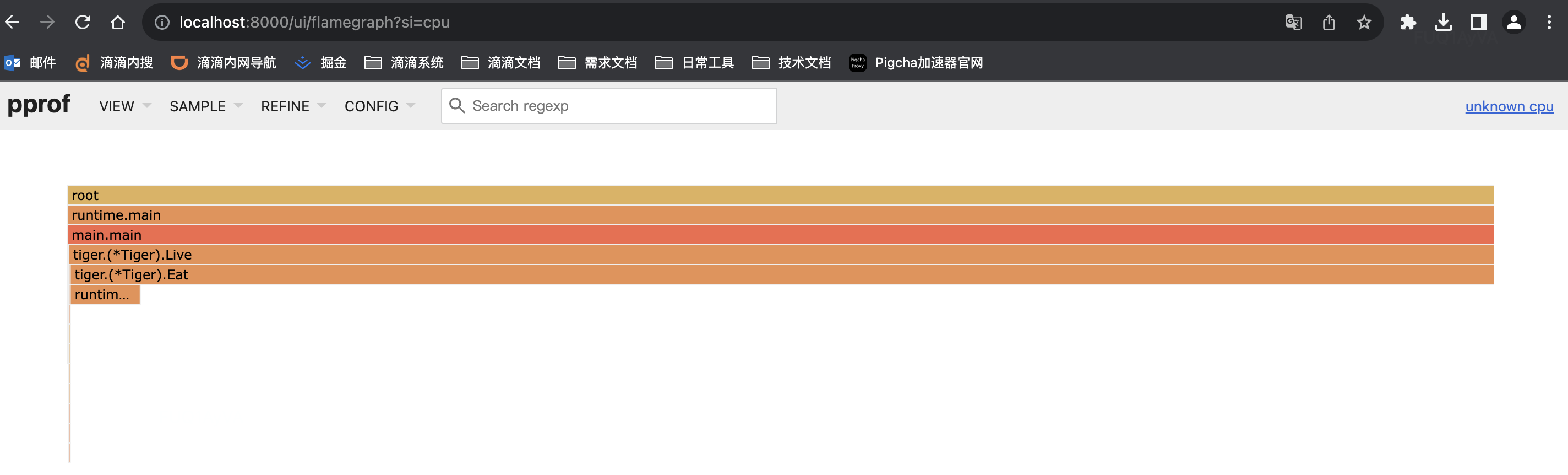
通过火焰图初步定位CPU占高是 github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat 造成的
步骤二:从局部分析具体引起CPU增高的代码位置?
方式一:通过Peek方式,打印每个调用堆栈,通过堆栈定位到代码位置
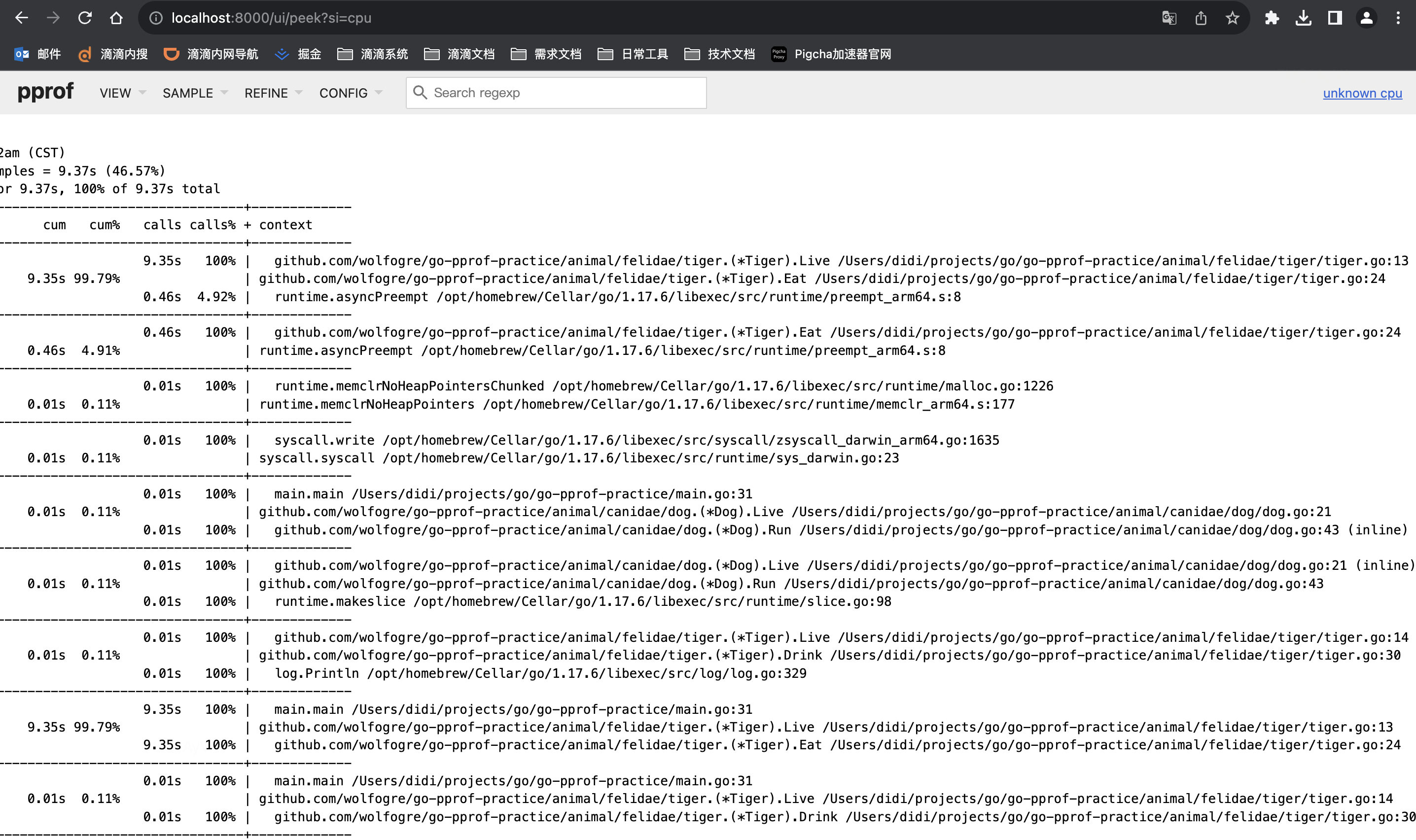
通过Peek图精确定位CPU占高是 /Users/didi/projects/go/go-pprof-practice/animal/felidae/tiger/tiger.go:24 造成的
- 方式二:通过Source方式,同go tool pprof的list命令
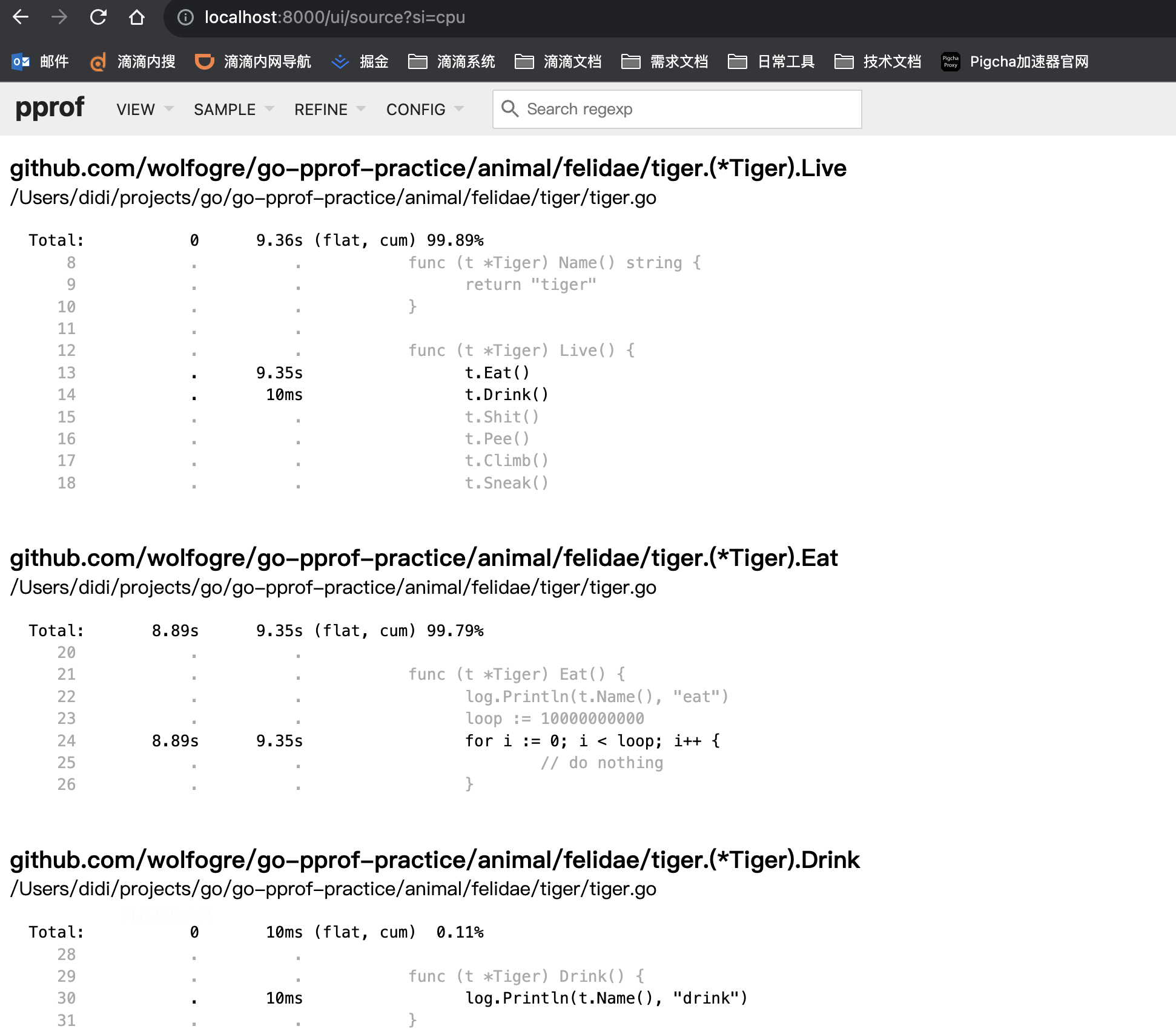
通过Source图精确定位CPU占高是 /Users/didi/projects/go/go-pprof-practice/animal/felidae/tiger/tiger.go:24 造成的
排查内存占用过高
类似CPU分析过程,基于HTTP接口分析,执行命令:
go tool pprof -http=:8000 http://127.0.0.1:6060/debug/pprof/heap
通过top查看
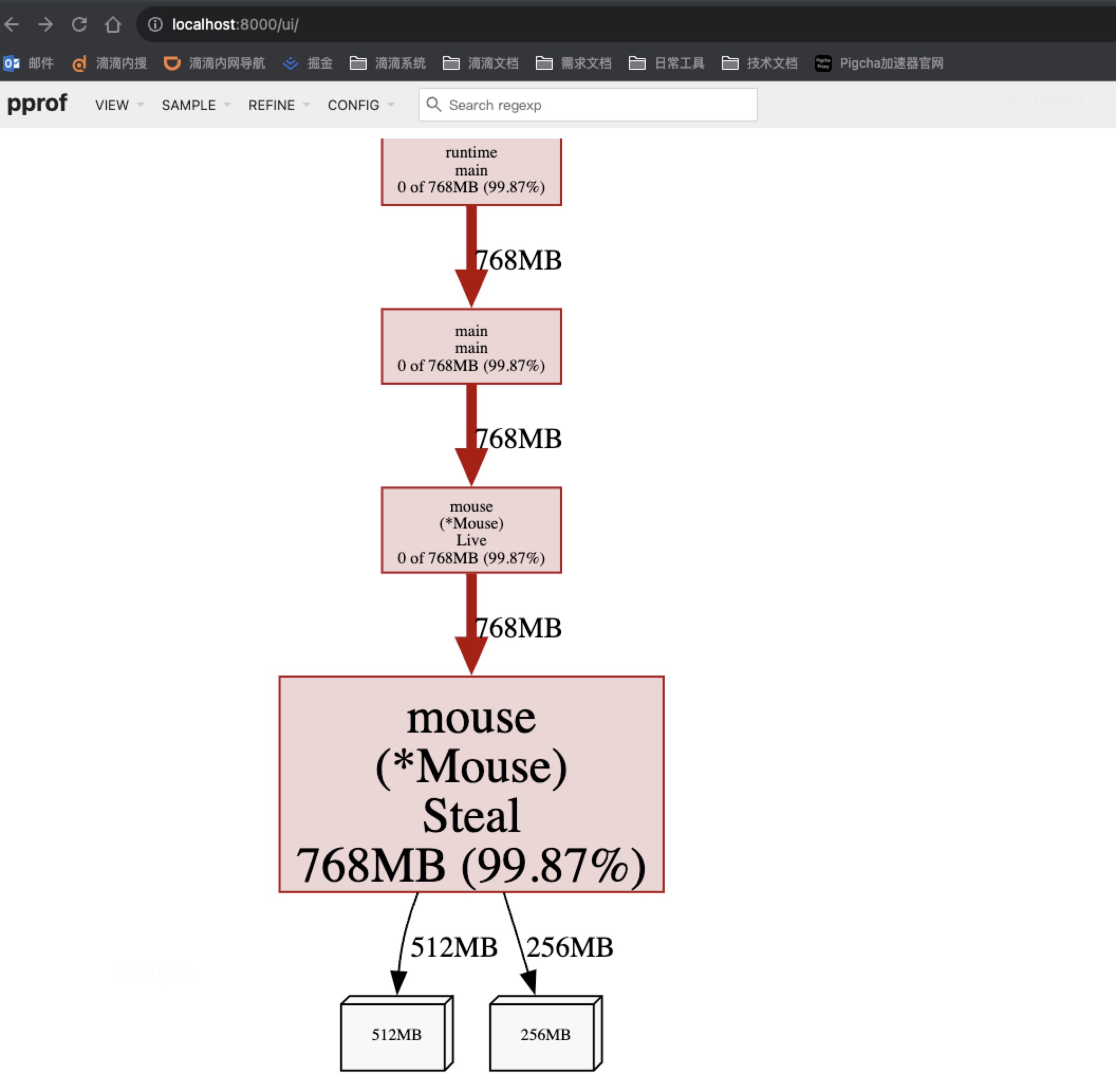
具体分析过程同CPU分析过程,不再赘述。
生产环境应用案例
公司内部:
https://i.xiaojukeji.com/way/article/1087878?lang=zh-CN
https://i.xiaojukeji.com/way/article/10618055?from=personal
公司外部:
https://taoshu.in/go/go-case-study-of-goroutine-leak.html
https://tech.dewu.com/article?id=11
实际应用问题
- 开启 pprof 会对 runtime 产生多大的压力?
开启后会对 runtime 产生额外压力, 采样时会在
runtime malloc时记录额外信息以供后续分析,可以人为选择是否开启, 以及采样频率等runtime 自带的 pprof 已经在数据采集的准确性, 覆盖率, 压力等各方面替我们做好了一个比较均衡及全面的考虑
当选择的参数合适的时候, pprof 远远没有想象中那般“重”
生产环境可用 pprof, 注意接口不能直接暴露, 毕竟存在诸如 STW 等操作, 存在潜在风险点
- 线上环境如何使用?
- 启动main函数导入
1 | _ "net/http/pprof" |
- 申请相应的机器权限,安装graphviz
1 | brew install graphviz |
Profiling 在微服务应用下的落地实践
Profiling可以为公司微服务基础组件建设提供一种思路,如同阿里的arthas,有些互联网公司在Docker已经集成arthas,部署服务的时候可以选择是否使用arthas。
线上使用Profiling存在痛点:
- 在线上服务器做 Profiling 也比较困难,首先需要申请各种操作权限登录线上服务器,然后安装 pprof、graphviz 工具生成可视化的 Profiling Report,流程比较繁琐复杂。而线上环境由于采用 docker 部署,也无法直接使用浏览器查看可视化的 Profiling Report(需要将原始采集文件拷贝出来)
- 触发 Profiling 的方式单一:一般而言,我们是在性能测试时或者生产环境出现问题的当下,手动发送 Profiling 请求。但是这种方式并不能有效应对线上的突发状况,自动生成 Profiling Report
- 不方便追踪和对比 Profiling 的结果:对于某个微服务而言,当我们检测到线上服务的性能下降时,会希望跟性能下降之前的 Profiling Report 做对比,以便快速定位性能下降的原因。现在为微服务生成的 Profiling Report 一般存储在开发人员本地环境,缺乏统一的管理,不方便日后追踪和对比。
以FreeWheel公司内部落地Profiling 可参考:https://www.infoq.cn/article/eqAzVi015lokJE9EjmLk
参考资料
[1] https://blog.csdn.net/phantom_111/article/details/112547713
[2] https://juejin.cn/post/7193865759825592375
[3] https://blog.csdn.net/qcrao/article/details/116334765
[4] https://www.cnblogs.com/qcrao-2018/p/11832732.html#%E4%BB%80%E4%B9%88%E6%98%AF-pprof
[5] https://segmentfault.com/a/1190000040152398
[6] https://darjun.github.io/2021/06/09/youdontknowgo/pprof/
[7] https://juejin.cn/post/6951078043922202631
[8] https://blog.wolfogre.com/posts/go-ppof-practice/#%E6%9C%80%E5%90%8E
[9] https://blog.csdn.net/dillanzhou/article/details/107032180
 WeChat微信打赏
WeChat微信打赏 AliPay支付宝打赏
AliPay支付宝打赏