
两阶段提交协议
背景:最近在看高性能MySQL,其中第7章节有简单讲到分布式(XA)事务,但是讲解的不够具体。另外自己之前对分布式事务的两阶段式提交原理理解不够深刻,借此机会来进行梳理一下。
何为分布式(XA)事务
首先分布式事务时针对分布式系统来讲的,在分布式系统中,事务的访问涉及的资源、参与计算的节点都部署在不同的节点上,这种情况下涉及到的事务称为分布式事务。
分布式事务的实现方式
因为分布式数据库数据库集群分布在不同的部署节点,如果需要进行事务保证,就需要协同不同的节点,通过多重机制保障节点之间数据的一致性等,相交于单数据库事务,多数据事务的问题变得更加复杂。目前,比较经典的实现分布式事务的机制是二阶段提交(2PC:two phase commit)和三阶段式提交(three phase commit)。因为实现成本和效率问题,二阶段提交在实际应用系统使用更加广泛。接下来要讲的也是二阶段提交。
两阶段提交协议
顾名思义,该协议将事务的执行过程拆分成两个阶段,准备(prepare)阶段和提交(commit)阶段。也可称投票阶段和执行阶段。
在两阶段提交协议中,有两种角色:
协调者(coordinator): 用于协调整个数据库集群节点的运行,该协议指定的协调者是单点
参与者(participants): 参与投票的数据库集群节点
2PC的第一阶段:投票
这一阶段主要目的是协调者初步询问数据库集群的各节点是否可以正常的执行事务,具体步骤如下:
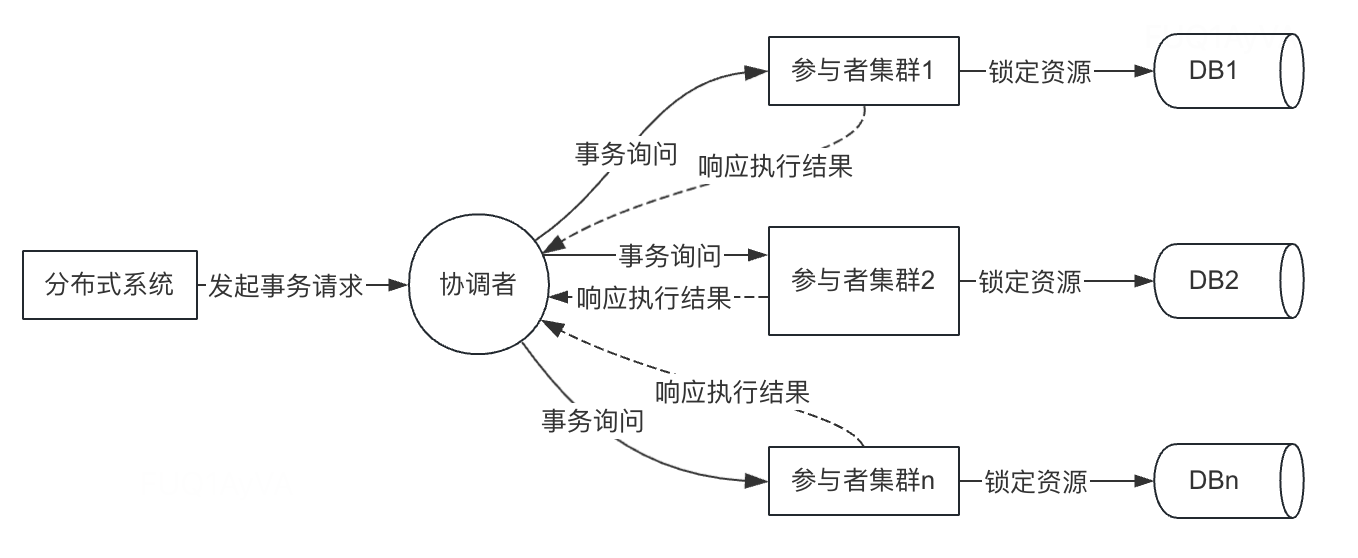
- 事务询问:事务协调者向所有参与者发送事务预处理请求,并等待参与者返回响应结果
- 执行本地事务:各参与者节点执行本地事务,但不进行真正提交本地事务,并记录事务执行日志
- 发送相应:各参与者节点向事务协调者发送自己本地事务的执行情况,同时阻塞等待协调者的后续指令
投票过程示意图如下:
2PC的第一阶段执行完后,由于各种原因可能出现3种情况:
(1)所有参与者全部回复执行本地事务成功
(2)1个或者多个参与者回复执行本地事务执行失败
(3)协调者等待参与者的响应超时
2PC的第二阶段:执行
根据第一阶段的响应情况,协调者会向所有参与者发送是否执行事务的通知,下面分别进行讲解:
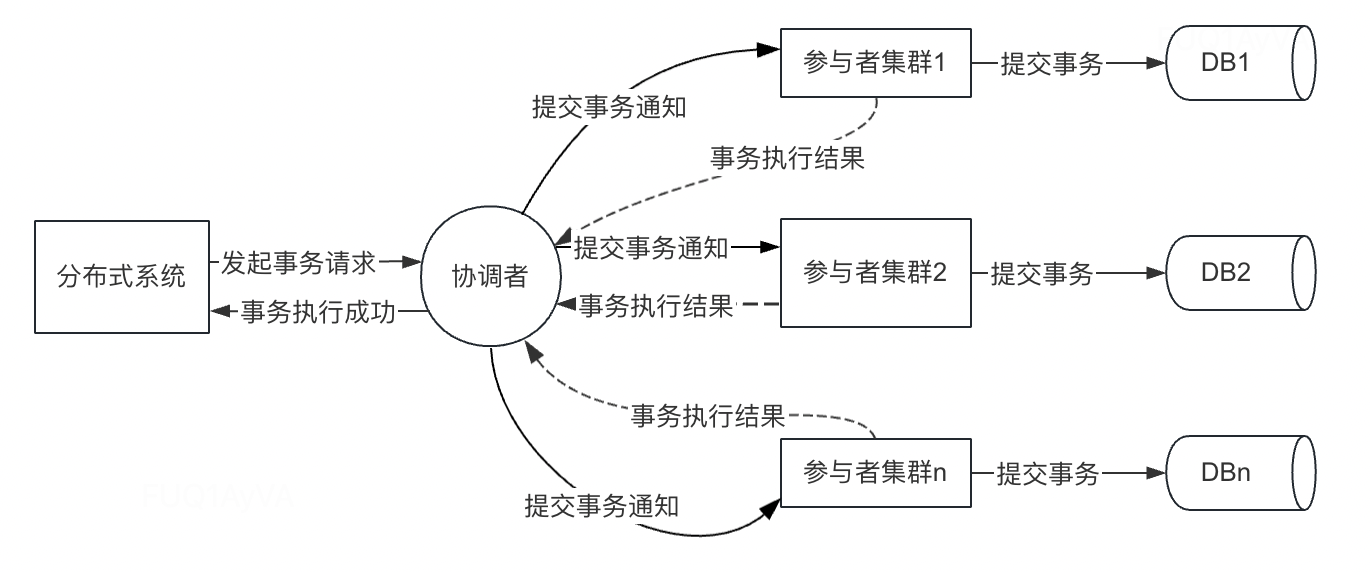
如果是上面的第一种情况,那么协调者会将所有的参与者发送提交事务的通知,具体步骤如下:
- 协调者节点向所有的参与者节点发送提交事务的通知
- 参与者节点收到提交事务通知之后执行本地事务的commit操作,然后释放占用的资源
- 参与者节点向协调者返回本地事务commit的最终结果信息
执行阶段针对第一种情况示意图如下:
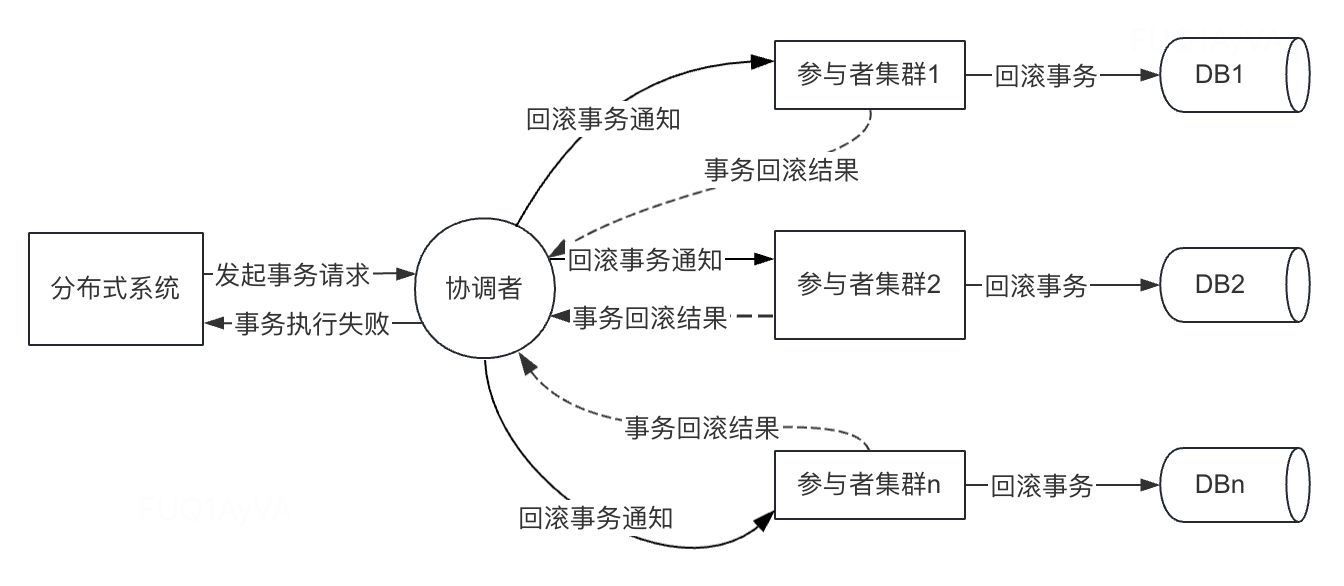
如果是上面的第二种和第三种情况,那么协调者均为认为参与者本地事务执行失败,需要执行事务回滚操作,具体步骤如下:
- 协调者节点向所有的参与者节点发送rollback事务的通知
- 参与者节点收到回滚事务通知的通知后,执行rollback操作,然后释放占用的资源
- 参与者节点向协调者返回本地事务rollback的最终结果
执行阶段针对第二种和第三种情况示意图如下:
两阶段提交协议存在的问题
通过上面的两阶段提交协议的分析可以看出该协议解决的是分布式数据库系统的强一致性问题,该协议的原理简单,易于实现,但是也存在一定的问题
单点问题
由于协调者会协调参与者节点的执行,一旦协调者发生故障,参与者会因为收不到通知消息,会一直阻塞。特别是2PC的第二阶段,如果协调者因为故障不能正常发送事务提交或回滚的通知,那么参与者将一直处于阻塞状态,数据库资源也一直被锁定,可能会导致数据库集群无法对外提供服务。
性能问题
两阶段提交过程中,所有参与者节点都需要听从协调者的统一调度,参与者节点在等待调度期间会进行阻塞,同时数据库资源也被锁定,如果投票过程持续时间比较长,这样可能造成性能问题
数据不一致问题
两阶段提交协议虽然是分布式的数据库强一致性协议,单仍然虽在数据不一致的可能性。假设在第二阶段,协调者发送了会务commit的通知,由于网络等原因只有一部分参与者收到了提交事务的通知,其余的参与者并没有收到事务的提交通知,则一直处于阻塞状态,这时候就造成了数据的不一致
2PC节点故障的情况
协调者正常,参与者宕机
由于协调者无法收集到所有参与者的消息,会进入阻塞状态。
解决方案:引入超时机制,如果超过规定的时间协调者未收到所有参与节点的消息,事务失败,协调者向所有的参与者发送rollback通知
协调者宕机,参与者正常
所有参与者节点都需要听从协调者的统一调度,参与者节点在等待调度期间会进行阻塞,同时数据库资源也被锁定
解决方案:引入协调者复制节点,如果检测到协调者节点宕机,需要重新选举出协调者节点,接管协调任务,并向所有的参与者询问状态
协调者和参与者都宕机
如果发生在投票阶段,因为所有参与者节点没有真正提交,对数据的一致性并没有影响。只需要重新选举出新的协调者,新的协调者重新执行投票阶段和执行阶段即可;
如果发生在执行阶段,并且所有的参与者节点在宕机之前并没有发送执行通知,这种情形下,也需要重新选举出新的协调者节点,新的协调者重新执行投票阶段和执行阶段即可;
如果发生在执行阶段,并且部分参与者节点已经收到协调者节点的通知,提交了本地事务。对于当前的情况,数据是不一致的,只能在重新选举协调者节点后,再通过补偿机制等把数据恢复成一致的,目前2PC无法解决该问题。
MySQL中的两阶段提交
MySQL每执行一条DML语句,先将日志写入redo log buffer,后续会一次性的将多个操作记录到redo log file,这种先写日志再写磁盘的技术就是WAL(write ahead logging) 技术,在这个过程中会使用两阶段提交协议。
在MySQL中,两阶段提交的核心就是binlog和redolog,其流程图如下:
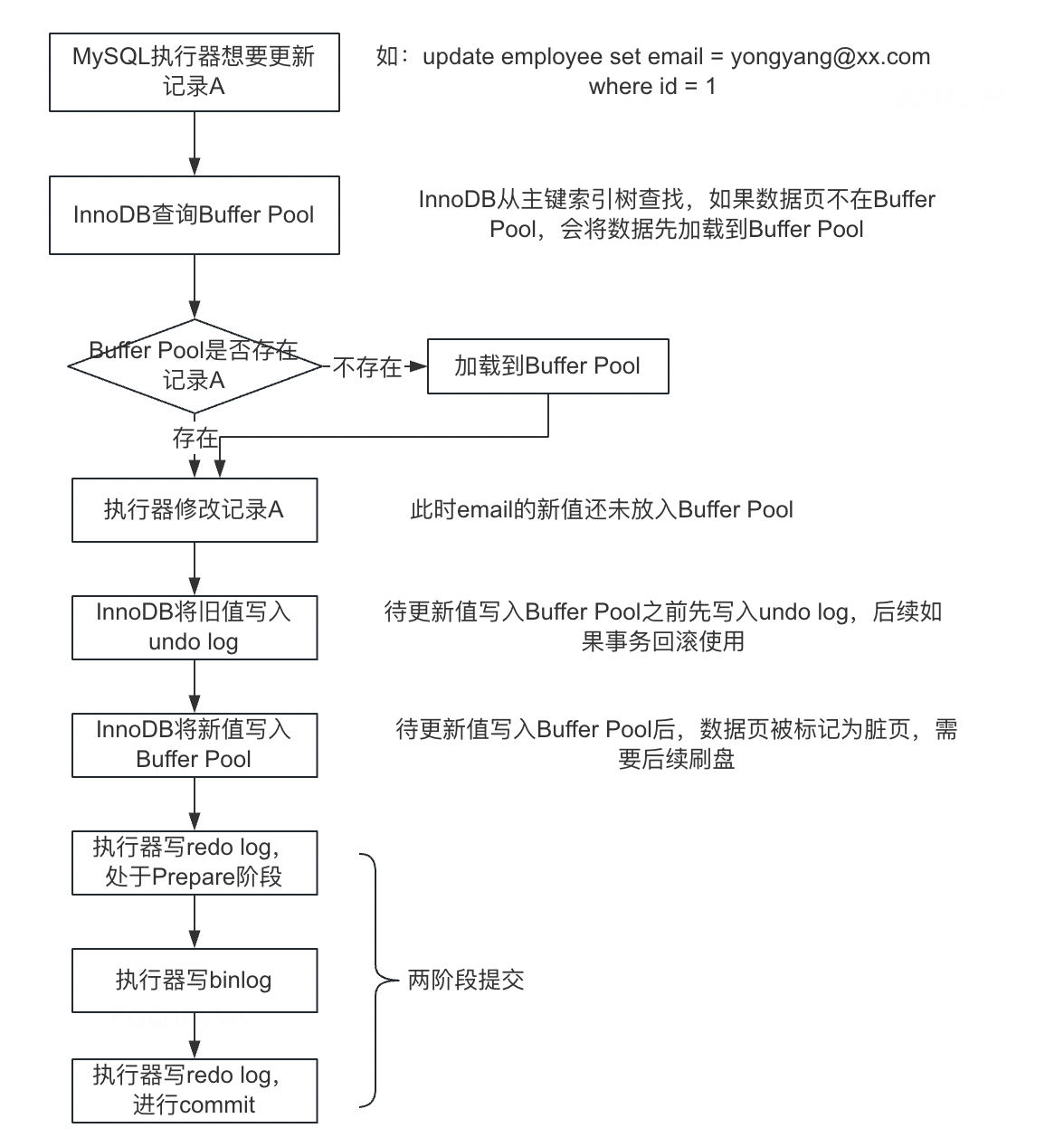
从上图可以看到,执行器在写redo log并不是一次写入,而是分成了Prepare和Commit两个阶段,这也就是两阶段的含义。
MySQL为什么需要两阶段提交
假设没有两阶段提交,那么redo log和bin log的提交,无非就两种形式:
先写bin log再写redo log
先写redo log再写bin log
针对第1种情况:假设我们在更新记录A的过程中,对于bin log写完后服务器崩溃,此时redo log还没写入。那么待服务重启恢复后就会存在问题,因为bin log已经存在记录,在通过bin log进行主从复制的时候,从节点能更新记录A。而此时redo log无记录A的操作日志,重新执行的时候,也不会对记录A进行更新操作,这样就会造成数据的不一致。
针对第2种情况:假设我们在更新记录A的过程中,对于redo log写完后服务器崩溃,此时bin log还没写入。那么待服务重启恢复后就会存在问题,因为redo log已经存在记录,在对redo log进行执行的时候,主节点可以成功更新记录A。而此时bin log无记录A的操作日志,这样在进行主从复制的时候,从节点无法执行记录A的操作记录 ,这样也会造成数据的不一致。
两阶段提交为什么可以解决数据不一致的问题?下面分别进行分析:
执行器写完redo log,进入Prepare状态后崩溃
执行器写完bin log后崩溃
执行器写完redo log,进行Commit后崩溃
针对第1种情况,因为服务器崩溃的时候redo log处于Prepare 状态,待服务恢复后,当前事务会进行回滚。此时,bin log日志未写入,所以不会复制到从库中
针对第2种情况,redo log的日志是不完整的,未进行最终提交。待服务器恢复后,当前事务会检查bin log的事务是否存在且完整,如果完整存在,则直接提交事务。否则,回滚事务
针对第3种情况,redo log在Commit阶段崩溃,其处理过程和情况2相同
作者结语:本篇就是分享的关于MySQL两阶段提交协议的内容,always day one!
 WeChat微信打赏
WeChat微信打赏 AliPay支付宝打赏
AliPay支付宝打赏